

如何在沉浸环境中真正感受到沉浸式体验?那就是,在虚拟场景中,依然可以实现与现实世界中一样的交互。例如,在体验一款游戏时,你可以直接使用你在虚拟世界的“数字化分手”,自然地与同伴打招呼、握手、击掌,还能完成各种抓取动作…..随着计算机视觉、AI等技术对自然肢体语言的识别, 不再仅通过手柄定义你在虚拟世界中的动作,正在成为可能。
这种通过手势识别打破次元壁,获得更佳临场感的方式,已成为当前VR、AR消费级头显设备重点研究的方向之一,但如果手部识别精度不够,则可能无法做到对真实双手姿态的完美复刻。为达到更好的效果,如何以更精准的方式同步还原人类双手在物理世界的灵动姿态,完成比手柄控制更精细的操作,就显得尤为重要。
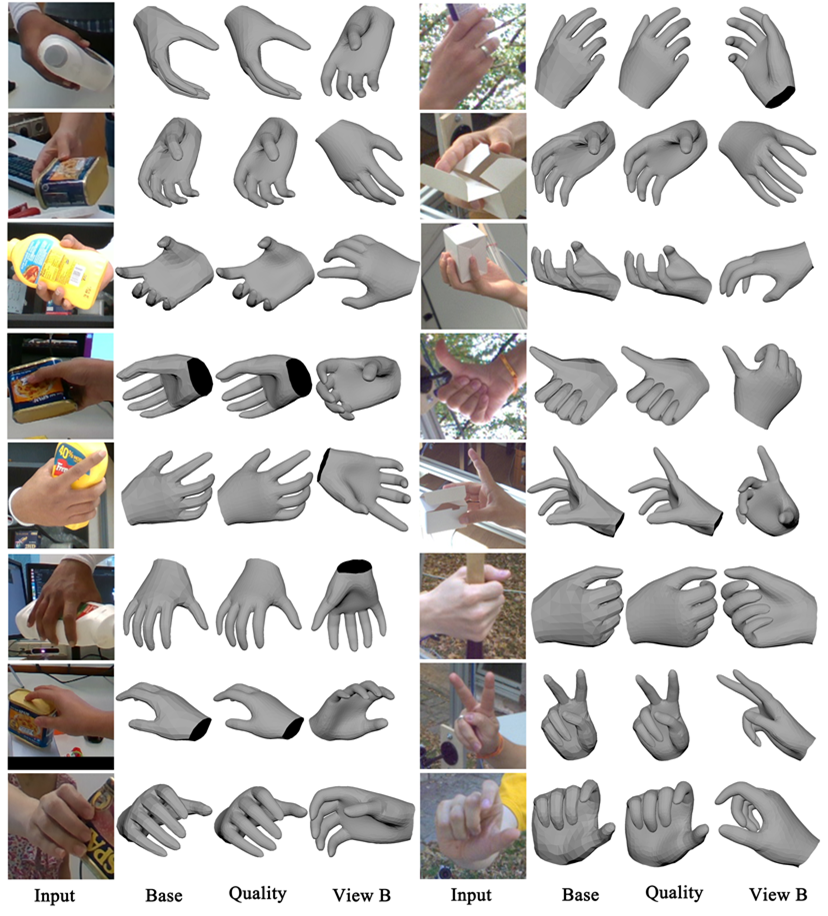
近日,爱奇艺的深度学习云算法小组通过题为《I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling》(I2UV-HandNet:基于图像到UV Map映射的3D手部高保真重建网络)的论文,针对现有模型在手部姿态识别方面不够精细等问题,提出一套I2UV-HandNet高精度手部重建系统,并依托爱奇艺在业内首提的将点的超分转化为图像超分这一先进技术思考,能够做到识别21个关节点和26自由度的手部运动信息,从而更有效地实现更高等级的手部还原。这将使得在VR、AR等使用场景下,用户通过更精细的手势追踪与识别,更准确、流畅地完成更多操作,享受在虚拟世界更佳的临场感。基于该系统的行业首创性和卓越应用价值,该篇论文成功被今年接收率仅为25.9%的国际计算机视觉大会(ICCV)成功收录,并在业内颇受认可的HO3D以及Freihand 在线测评榜持续数月排名第一,超越目前的SOTA水平(若某篇论文能够被称为SOTA,就表明其提出的算法(模型)的性能在所在领域为最优)。
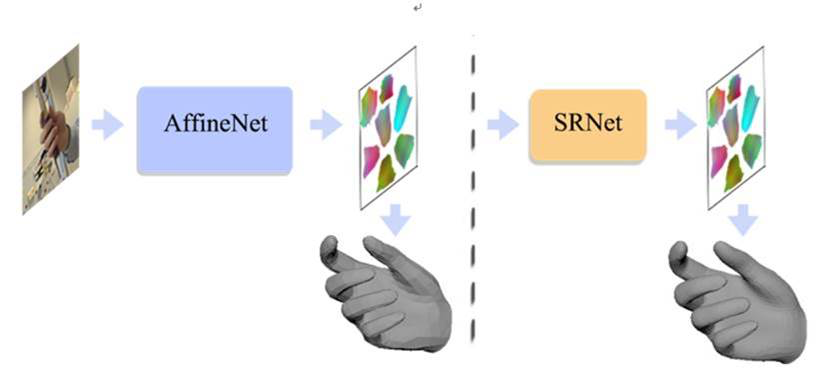
I2UV-HandNet高精度手部重建系统技术实现示意图
通常而言,要让手势识别实现更高的精度,首先需要好的手部模型,只有好的模型才能预测出来更多3D点。同时需要有足够的高精度数据,才能不断训练重建模型。基于大量手部数据对深度学习算法的“喂养”,爱奇艺自研的I2UV-HandNet高精度手部重建系统,能够通过UV重建模块AffineNet,完成由粗到精的人手3D模型重建。这样一来,即使在大遮挡或多姿态状态下,该系统仍可有效改善现有人手模型识别不准确等问题,为手势识别提供更为完整且精准的参考。
同时,考虑到不同虚拟场景对手部3D模型的精度要求不一,该系统还可通过SRNet网络实现对已有人手3D模型更高精度的重建。该系统基于落实“点的超分转化为图像的超分”的先进技术思考,通过算法从低精度UV图到高精度UV图的学习,可完成MANO(778个点/1538个面)人手模型向高精度(3093个点/6152个面)乃至更精细(上万点云)的人手模型的重建,这可以实现双手的“虚拟分身”在不同背景色彩、景深下,表现得如物理世界双手一样灵活。
值得一提的是,未来该系统将应用于下一代奇遇VR中,赋能爱奇艺VR更佳的沉浸感,让用户不仅仅是浏览内容,更有机会“走进内容”。可以预见,该系统基于更低成本的深度学习算法完成的高精度手势识别,相比通过自带深度信息识别的摄像头,将更具性价比和规模化落地的商业潜力,也将为爱奇艺更多业务场景或硬件终端增强“沉浸体验”带来更为强大助力。



























































































